Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM




AI Testing Tools for Web Apps Best AI Testing Tools for Web Apps As enterprise applications get more complicated and automation suites contain thousands of test scripts, AI-powered tools for test Web Apps are the newest hot topic in the field of Web Applications. The key benefit of AI-powered tools over conventional tools like Selenium […]
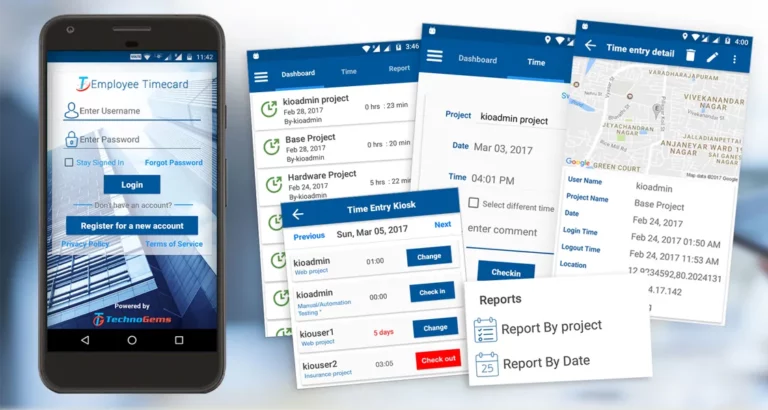
Employee TimeCard — Remote Work — Geofencing Employee TimeCard Employee TimeCard is the perfect solution for business with ONSITE OFFSITE, and MOBILE employees where TIME and LOCATION need to be accounted. Employee TimeCard collects time and GPS location allowing employers to setup GEOFENCING and confirm the location of their employees as they work onsite, offsite […]

DevOps for Mobile Apps How to build and launch hundreds of applications in days? Software developers are often challenged with building custom apps for different markets or different industries, or different customers from a base application template. These are often developed as white label solutions. These custom apps can improve branding and customer retention. Brand […]

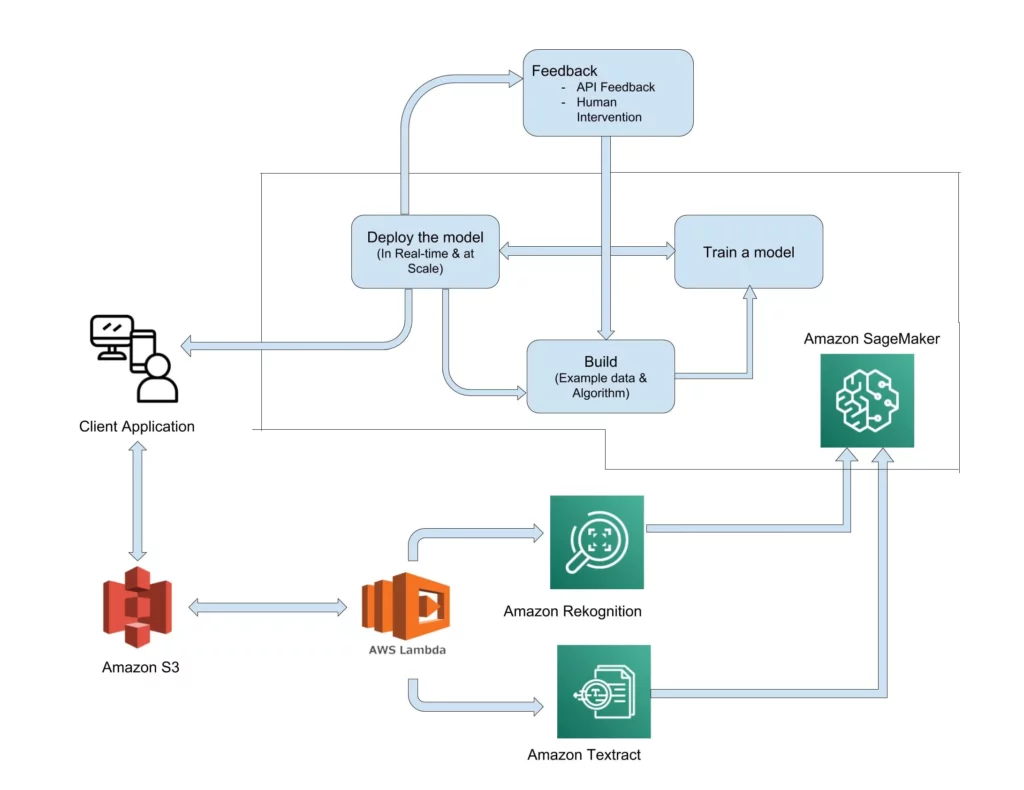
AI-enabled Open source Framework to optimize Machine Learning Enabling developers to train machine learning models once and run them anywhere in the cloud and at the edge. Amazon SageMaker Neo runs fast on less memory consumption, with no loss of accuracy. Challenge Machine learning offers a wide variety of benefits but it is hard for […]

Modernize Your Application with AWS A modern approach to deliver ‘innovation’ and ‘value’ to your customers! Within the cloud computing world, Amazon Web Service (AWS) is the most acceptable technology. It is set to be most prominent and successful service with its size and presence in the field of application development. Being a secure cloud […]

DevOps – A Modern Approach to Software Delivery Technology has evolved over time. And with technology, the ways and needs to handle technology have also evolved. Last two decades have seen a great shift in computation and also software development life cycle. The key to quickly fixing delays in software development lifecycle lies in establishing […]

Exploring the Future of Web Application Development In the ever-evolving landscape of technology, web application development stands as a pivotal force driving innovation and business expansion. These applications have seamlessly integrated into our daily lives, offering versatility and convenience that positions them as the preferred choice for businesses aiming to provide a smooth and hassle-free […]

In today’s competitive business landscape, delivering a top-tier customer experience is essential for retaining loyal customers and standing out in the market. One effective way to elevate this experience is by leveraging white-label software solutions. These ready-made platforms, customized with your brand’s identity, enable businesses to offer high-quality services without the long development timelines or […]
